

一、简介
Stable-Diffusion 是时下最流行的人工智能绘画的项目,没有之一,之前由于的二次元训练模型效果十分出色也成功使Stable-Diffusion破圈。之后因为NovelAI的训练模型和官网的前后端泄露,更是直接让AI绘画成为热门话题。经过这一段时间广大网友的开发及探索,涌现出了众多的一键包之类的便利产物。今天我也赶个末班车教大家如果想为其他人提供AI绘画服务应该怎么办。
二、本地 or 云端,该如何选择
首先我们要思考一个问题,不要跟风去凑热闹。首先你要分析自己的需求,再分析自己的成本问题。
需求:你是否真的需要自建AI绘画?
1、只是满足自己的好奇心。
那么只要去B站搜索免费的AI绘画,就可以找到一大批热心人士提供的网站或者机器人供你短暂的游玩。虽然本站也自建了开放给会员使用,但是不对外公开,主要是平常我自己在用,如果后面我感觉可持续就会持续性开放,反之就直接关掉自己本地临时跑。
2、有长期出图的需求
有长期出图的需求肯定得使用自建的服务了,或者付费给官网、其他服务提供者。毕竟大家都清楚免费的服务是长久不了的,之前的大乘AI前前后后花了几万刀的出来的结论在那里。
自建又分为两种情况。一种是单纯的出图需求,没有图片画风或者规格的限制,还有一种是想要客制化画风的那种。
2.1 纯出图,念咒语
这种可以考虑你自己的电脑是否能够胜任这个任务,有一个不错的显卡可以让你在本地搭建起一个服务了。如果你只是单纯自己的玩,就算是显卡渣一点也没事,也就出图速度相对而言会慢一点,无法生成大尺寸的图片罢了。
如果你是想持续用网页或者机器人提供服务,你也可以选择按本教程来选择一个GPU服务器来提供线上服务。
如果你本地没有电脑或者电脑没有一个好显卡,那么我首先推荐你去colab或者百度飞桨这种免费的算力提供平台。这种平台除了每次使用都要重新配置之外基本上可以说是没有其他缺点了。
2.2 想要独特的画风,需要训练模型
这种情况我是强烈推荐你选择去云服务产商租用一个GPU服务器去训练的,因为训练模型十分的耗时耗力,举个例子,平常我用腾讯云的 ,搭建的NovelAI版的出图服务,一张默认参数28Steps的图一般是10秒出一张图,每步耗时0.36s。你如果想训练独特的画风模型。首先你需要准备至少30张以上的图,每张训练5000步以上,才能让模型能够较为鲜明的模仿出画风。
30*5000*0.36=54000s=15H
这样我训练一次模型最起码得15小时,这15个小时之内GPU是满载运行的,你就不能动他。你想要更好的效果还得更长时间。所以这种情况我是强烈推荐不要在本地训练模型的,除非是能白嫖实验室里的算力的那种(不建议)。上云之后基本上数据准备好,跑就完事了,你自己该干嘛干嘛,本地训练你就基本上不能用电脑了,电脑噪音也会烦死人的。
成本:
本地有电脑自建:金钱成本为0,除了要下载数据搭建环境之外就是时间成本了。
白嫖colab,飞桨:金钱成本为0,时间成本较大,无法持续性提供服务
自建:金钱成本最低2块钱一天,80块钱一个月。
腾讯云的GPU云服务器目前来说算是市面上最便宜的了

如果你要公开为他人服务的话建议别直接暴露GPU服务器IP,可以走CDN,我的做法是多开一台同地域的,然后通过内网让GPU只处理图片,web端由轻量来处理,这样做的好处就是你不用担心你的GPU服务器遭到攻击,顶多web端服务器不能用,但是如果用来对接QQ、telegram机器人的话还能继续使用。

如果你想保存生成的图片也可以选择多买一块硬盘,用来保存生成的图片。目前默认的尺寸512*768的大小一般是500KB左右。假设每天运行时间约为一半时间一天生成的图片大约有2GB,你可以参考一下是否选择额外的云硬盘。
如果需要大规模应用的话,只一台GPU服务器肯定不够用的,这里考虑到成本的问题推荐大家可以尝试竞价实例。另外新加坡的竞价实例目前最低0.5折,而且出口的话也可以走新加坡的轻量服务器,上行带宽相较于国内的服务器更大,更利于图片的传输。
三、GPU服务器安装NovelAI
3.1、GPU服务器购买设置
GPU服务器我这里选择的是GN7 8C32G 1 T4 GPU。因为考虑到后续我可能拿GPU做一些其他的事,为了更加便捷我这里选择的是Windows server 2019,这款的话没办法后台自动安装GPU驱动,所以大家购买的时候需要注意一下。了解基本linux操作的,可以选择linux系统如Debian、centos、Ubuntu,

选择linux系统可以直接勾选后台自动安装GPU驱动即可,驱动版本可自行选择,我这里不做演示。
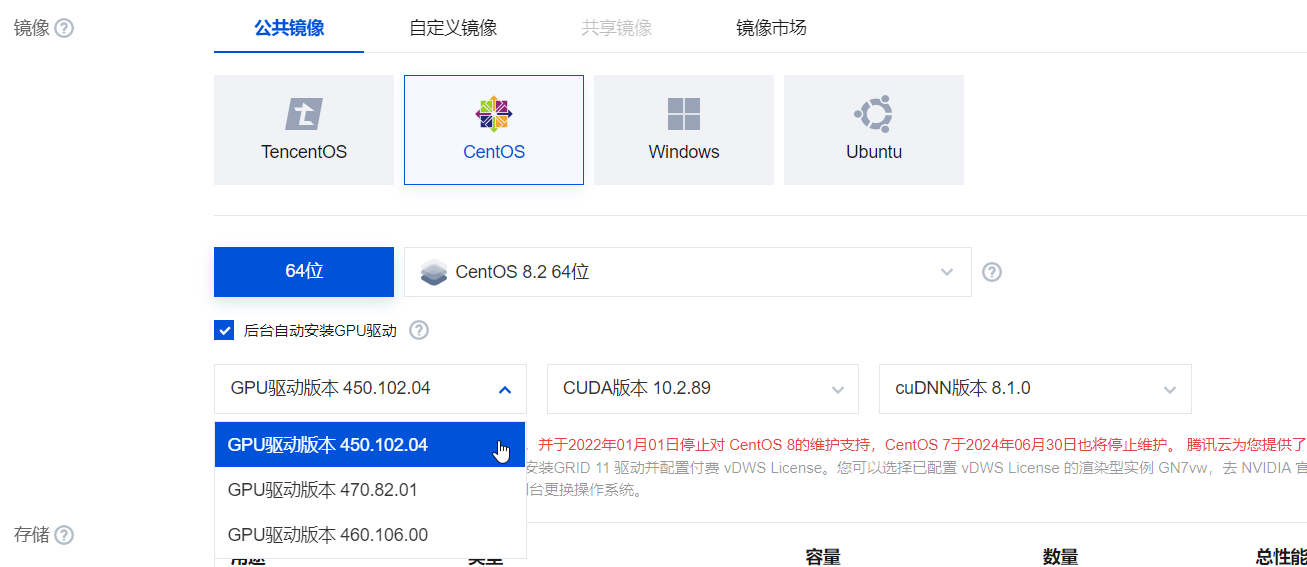
然后一路默认或者根据自己的情况进行微调即可。
3.2、GPU驱动安装
3.2.1、登陆GPU服务器
由于我前期选择的是Windows系统,所以我这边需要先安装一下GPU驱动。
直接电脑远程桌面连接到GPU服务器。登陆GPU服务器管理后台,选择登陆——>下载RDP文件

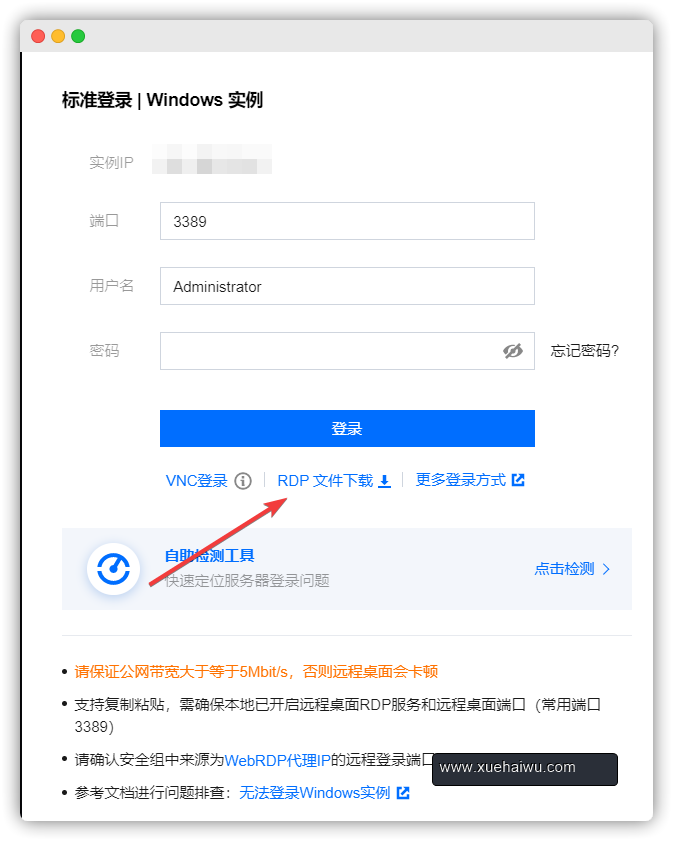
然后电脑上直接双击RDP文件就能快速登录到远程服务器上了。
3.2.2、安装NVDIA Tesla 驱动
访问官网
选择对应显卡及对应系统、语言选项,再从中选择合适的那个,我这里选中的是 CUDA Toolkit版本11.7的
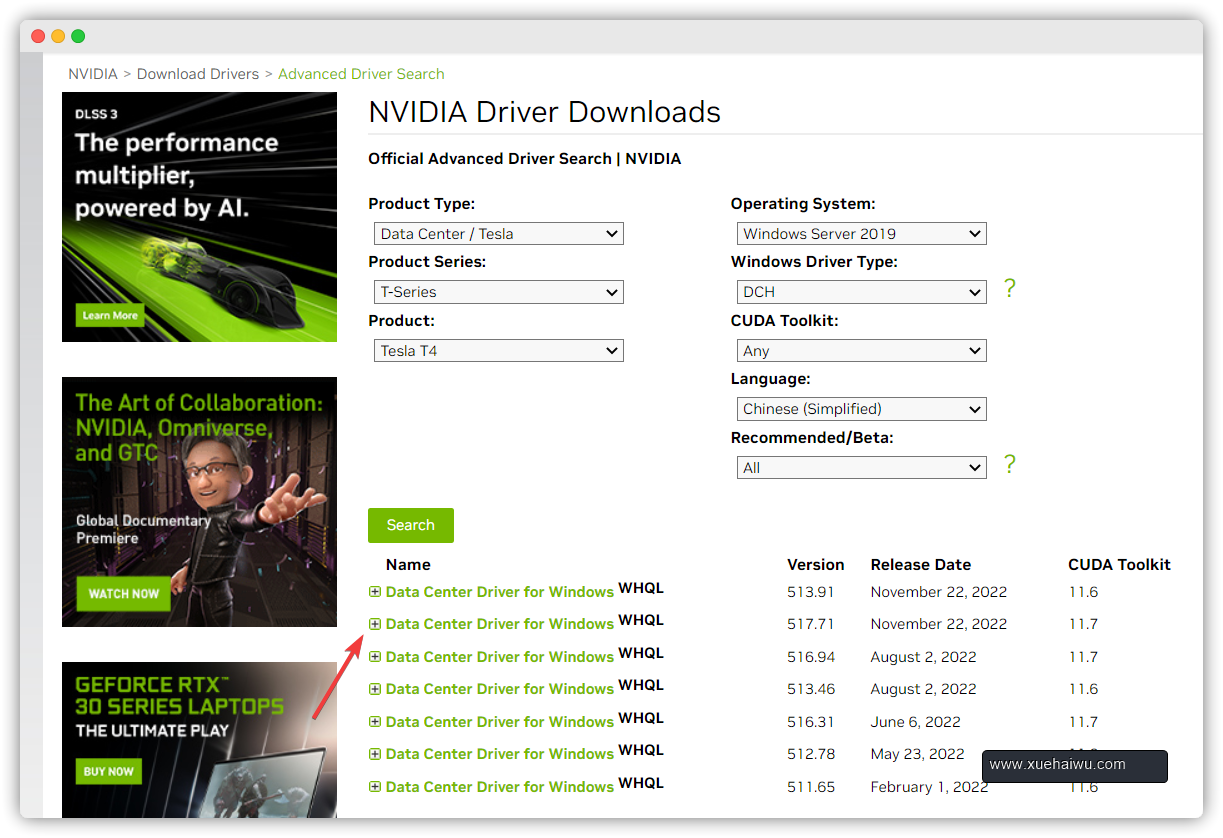
点击下载即可,然后像普通软件那样安装就行。
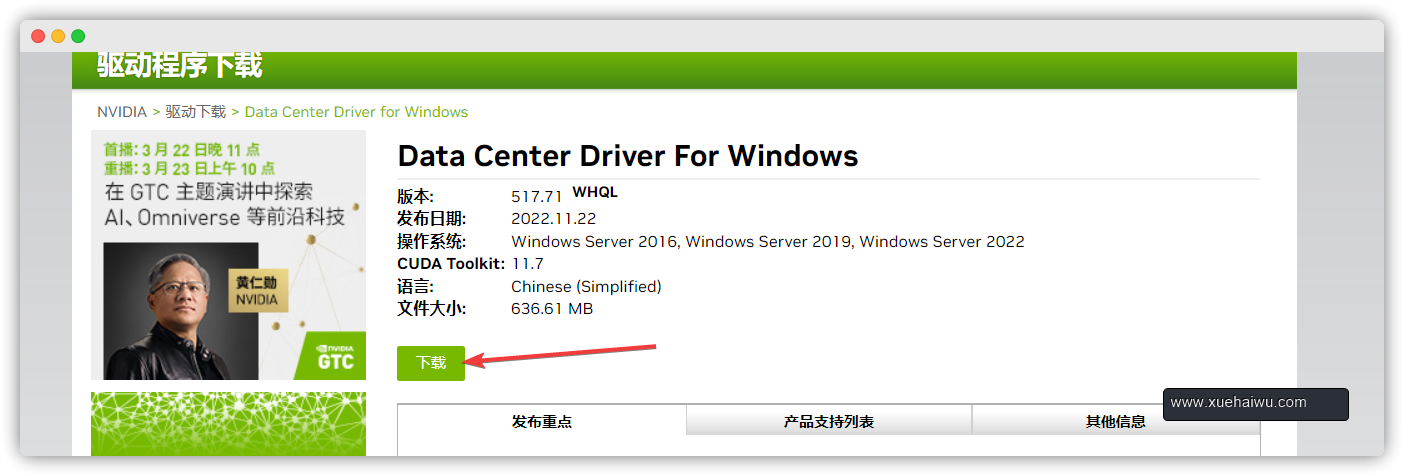
3.2.3 安装CUDA驱动
访问官网,选择合适的版本,这里以CUDA Toolkit 11.7为例
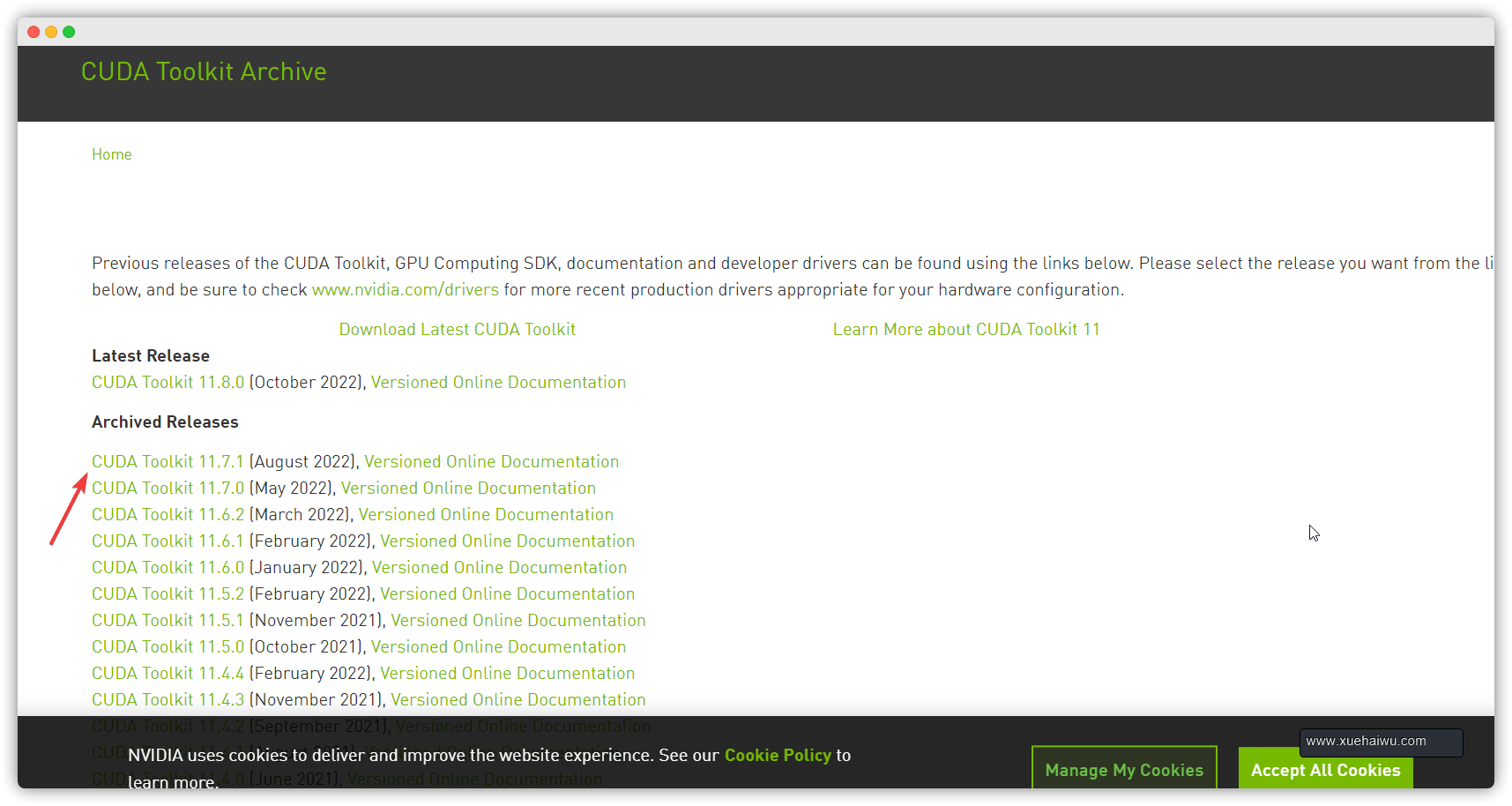
选择自己的系统版本以及安装模式,我这里选的是本地安装模式,你也可以选择网络安装模式,但是网络安装模式有可能会因为网络质量问题导致安装失败。推荐大家根据自己的需求来进行选择。
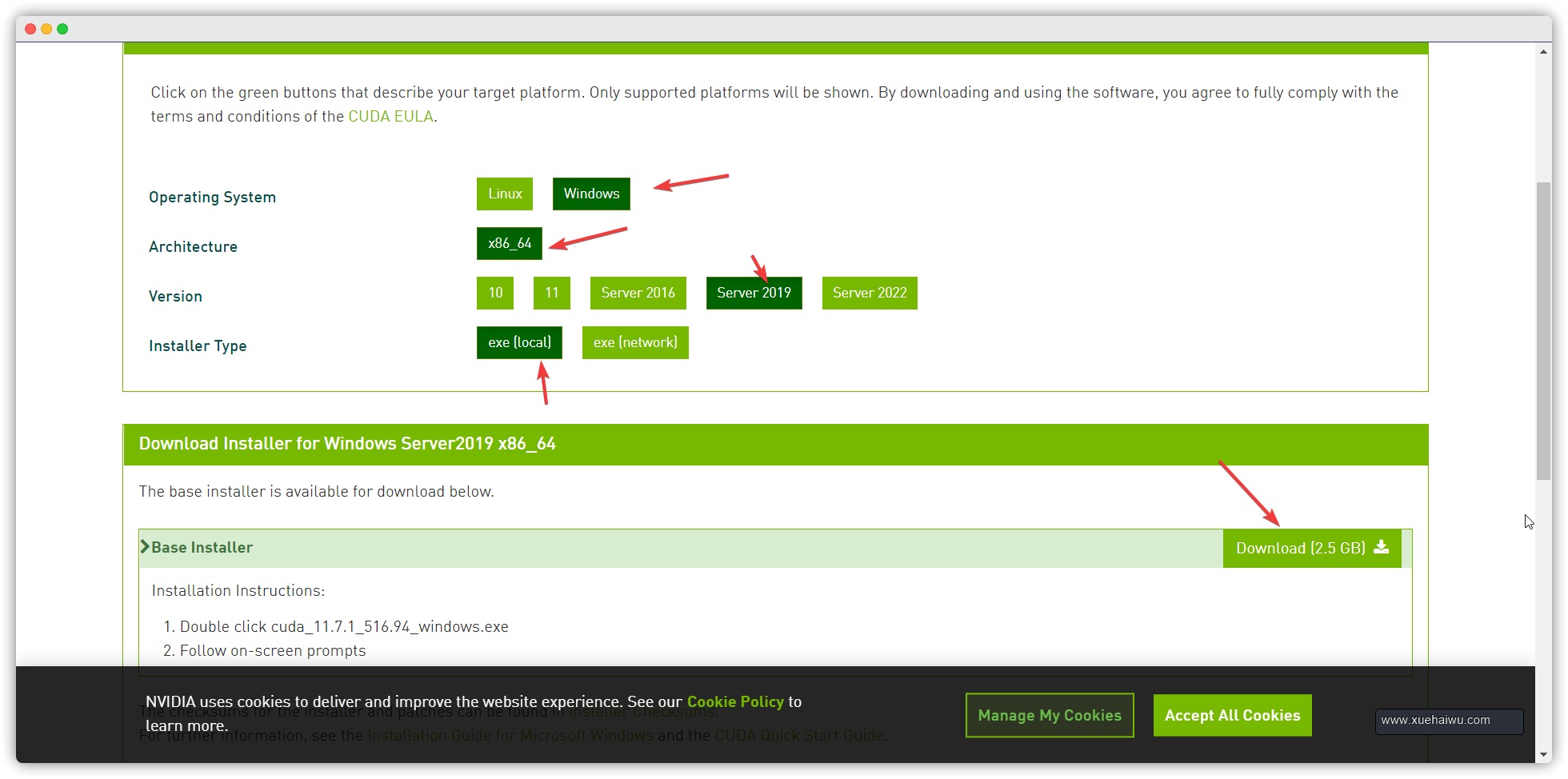
选项也是直接一路默认就行。
3.2.4 确认是否安装成功
确认很简单,直接win+R键然后输入CMD回车
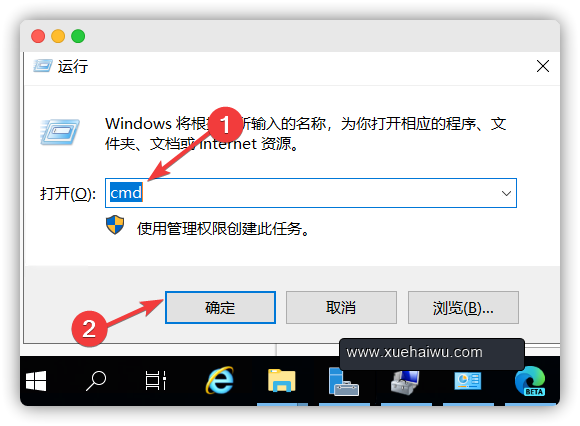
然后运行以下命令即可查看显卡状态
nvidia-smi #输出当前显卡状态 nvidia-smi -l 10 #每隔10秒输出一次显卡状态
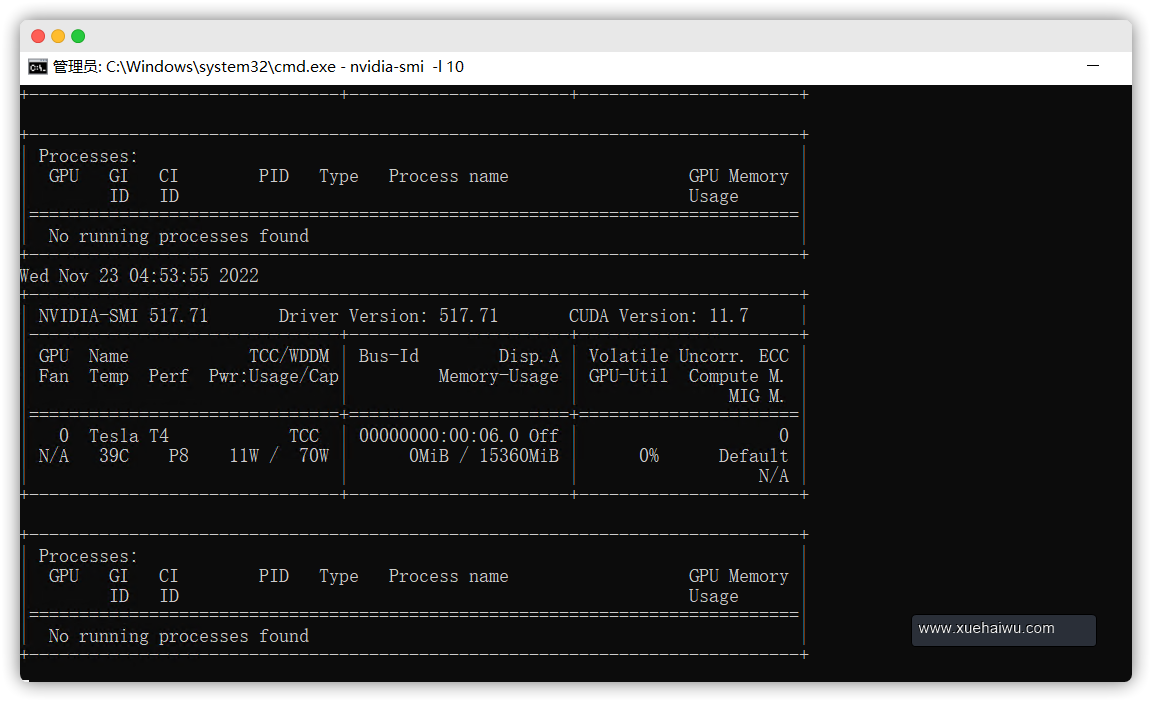
然后就可以一直挂着,方便我们查询显卡状态。
3.3、下载NovelAI包
由于NovelAI有好几个版本,也有人更喜欢,请自行选择合适的版本并且按照该版本的使用方法进行食用。
我这里选择的是naifu版,相对来说简单易用吧。
下载地址:
磁力链接:magnet:?xt=urn:btih:4a4b483d4a5840b6e1fee6b0ca1582c979434e4d&dn=naifu&tr=udp%3a%2f%2ftracker.opentrackr.org%3a1337%2fannounce cloudflare R2: https://pub-2fdef7a2969f43289c42ac5ae3412fd4.r2.dev/naifu.tar
我这里推荐用磁力链接的方式,因为R2服务器在海外,所以传输速度一般,磁力链接基本上能跑满。
这里我推荐下载,然后通过qbittorrent来下载磁力链接。由于GPU服务器在国内,qbittorrent的官网下载地址是海外的,所以推荐大家可以先下载到本地,然后上传至同地域的COS里然后再进行下载。也可以先获取到我服务器里的软件链接,再去GPU服务器下载,总之哪样方便就用哪样。
3.4、Python环境设置
由于后端程序都是用python写的,所以还要安装python。
我们直接上下载即可,或者下载本文末尾的工具包
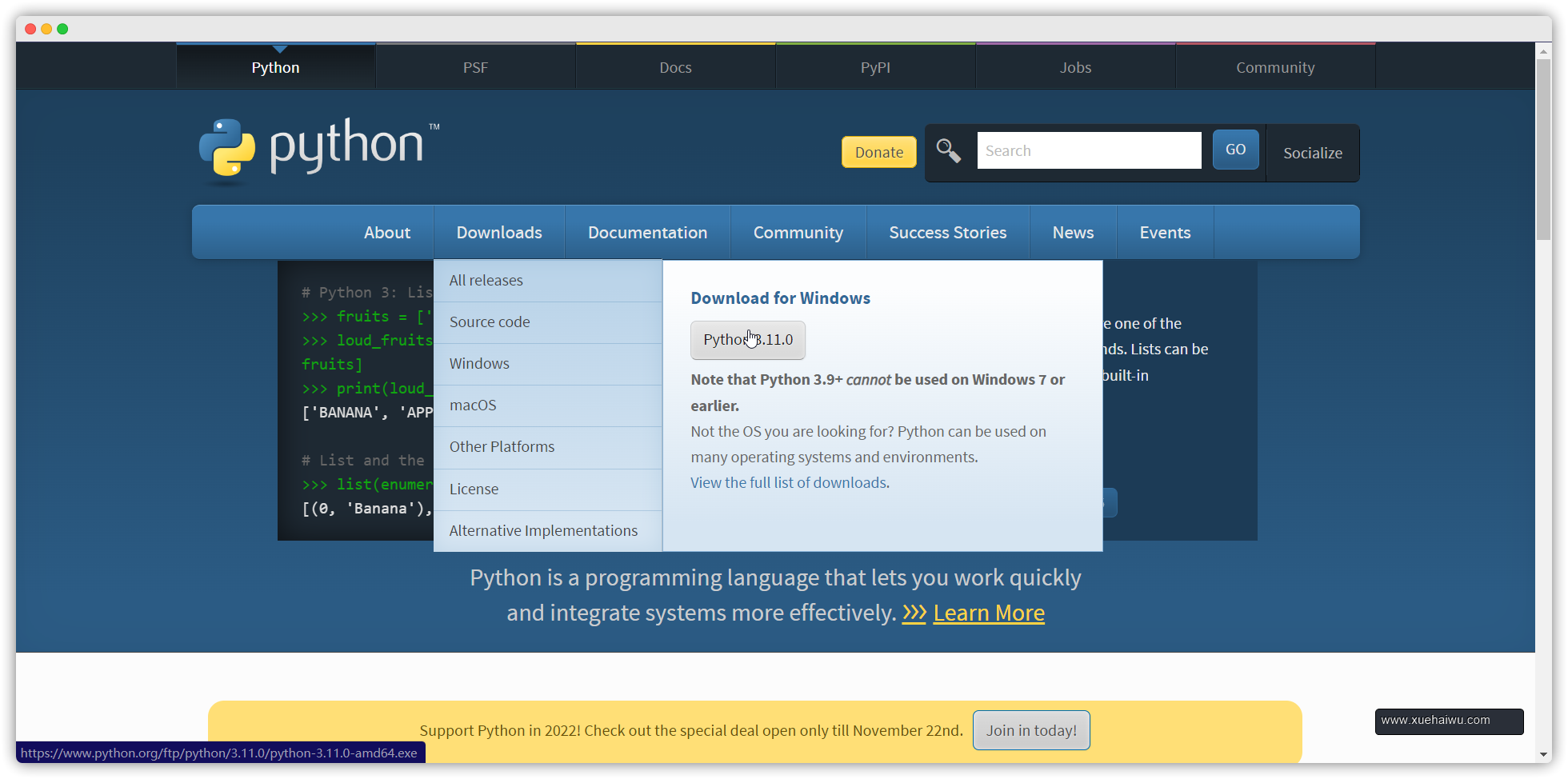
安装的时候一点要注意先勾选Add python.exe to PATH然后默认安装即可。
3.5、运行NovelAI
先将naifu压缩包解压,然后再解压program.zip到当前位置
最后再双击运行setup.bat文件进行初始化设置即可。首次初始化完成之后以后就可以直接运行run.bat提供服务了。
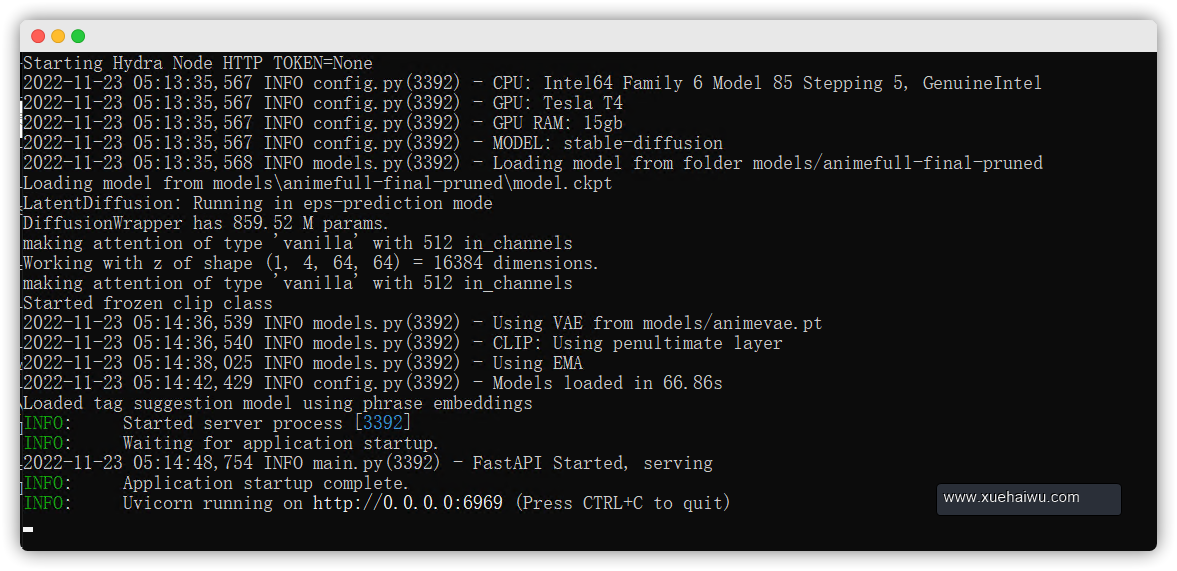
然后打开GPU服务器里的浏览器输入就可以进入到NovelAI经典页面了。
http://localhost:6969/
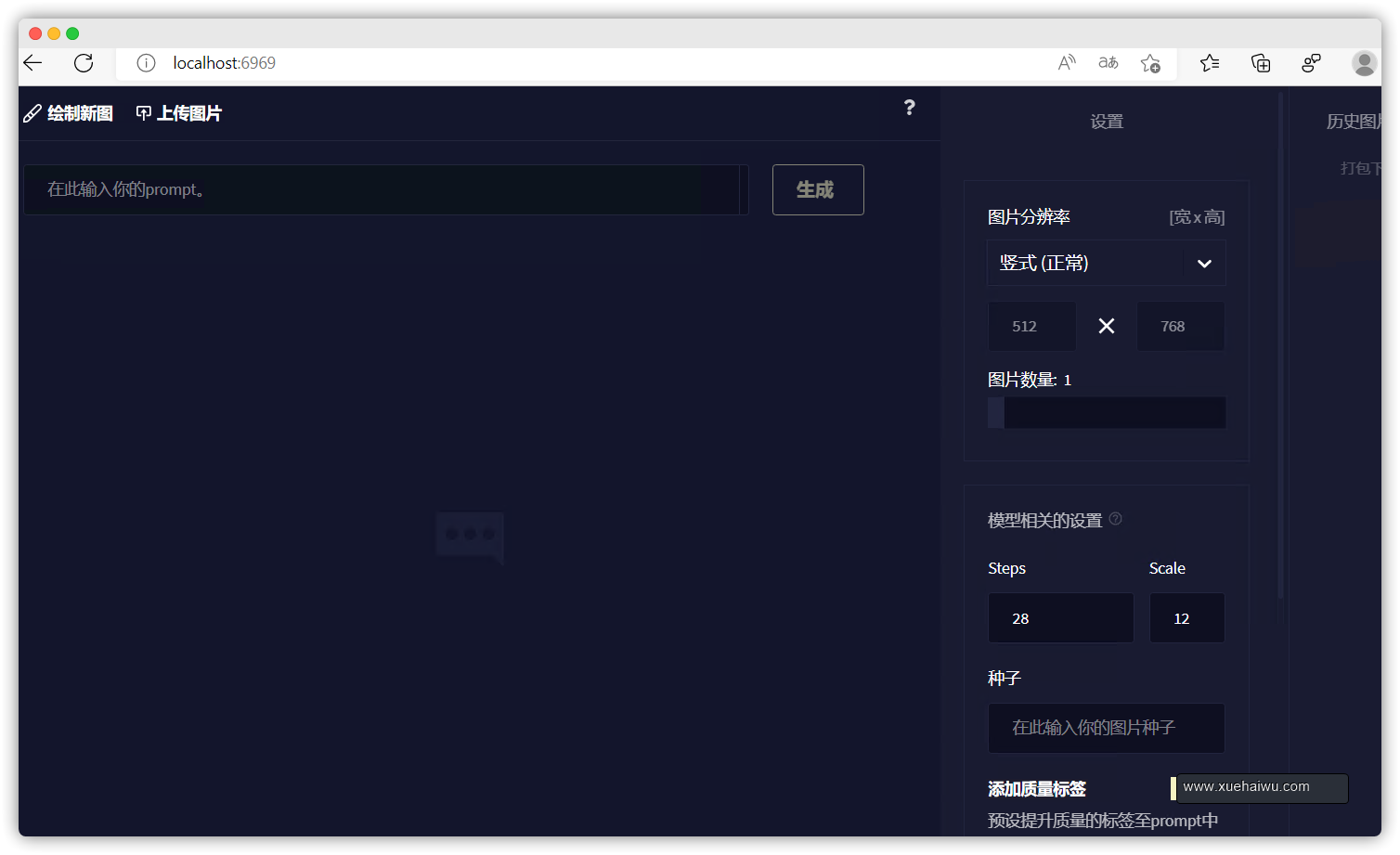
四、二次开发及汉化
二开其实我更推荐使用Stable Diffusion WebUi,不过由于面对用户的话NovelAI确实更好一点,这里只简单介绍一下二开和汉化,有兴趣的可以直接去参考Stable Diffusion WebUi或者基于原stable-diffusion项目进行开发。总的来说都是参数设置的问题,只是不同的UI罢了。
如果要对NovelAI进行二开,下载的压缩包里有program.zip(项目后端)frontend-src.zip(项目前端),前端的技术栈是React+next.js,二开的基本上都是程序员,这里我就不再多BB相信有能力的都会用。
汉化的话我这里有一个自制的汉化包,只是简单的汉化了一下,部分词我觉得没必要汉化就继续保留了。
如果你想用我的汉化包的话,可以下载汉化包,将里面的staticcn.zip解压并覆盖原static文件夹即可。然后重新启动一下程序就行。
五、其他设置
5.1、NovelAI设置
可以通过修改run.bat来进行详细设置默认设置下,根据预设图片大小生成速度为1.5-2.4step/s,生成一张图大约耗时10-20秒
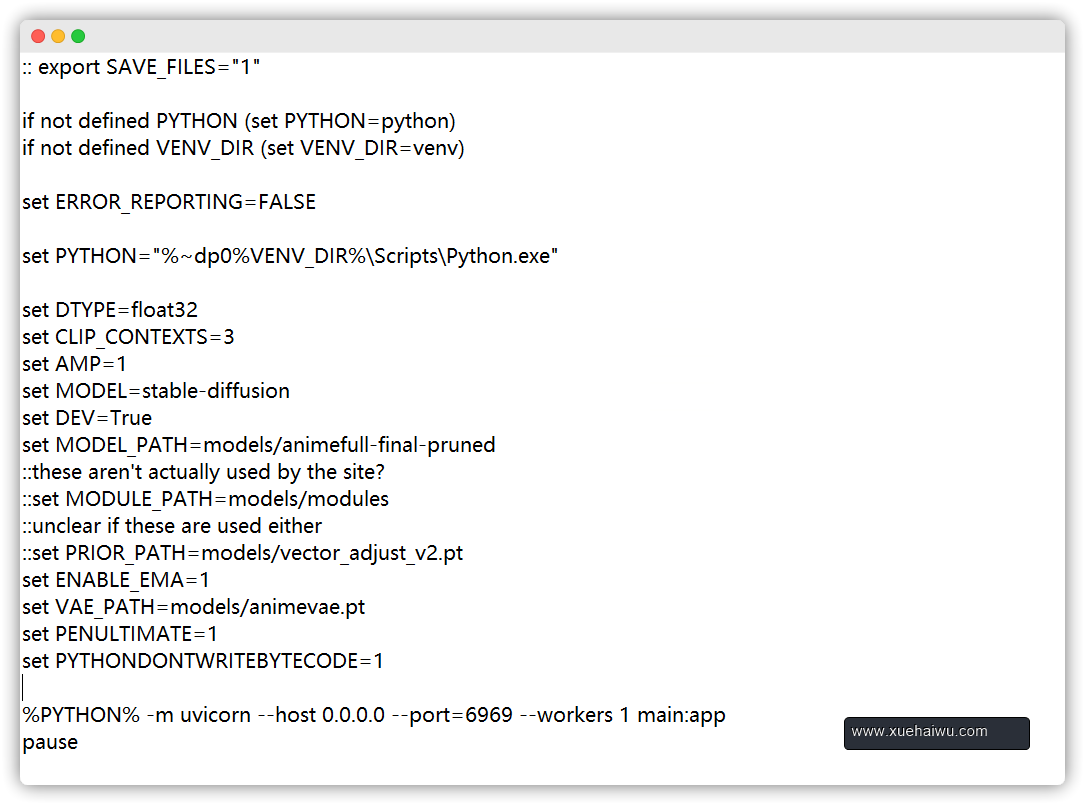
5.2、WEB服务设置
要想其他人能访问到前端页面还得开启服务器的安全组端口
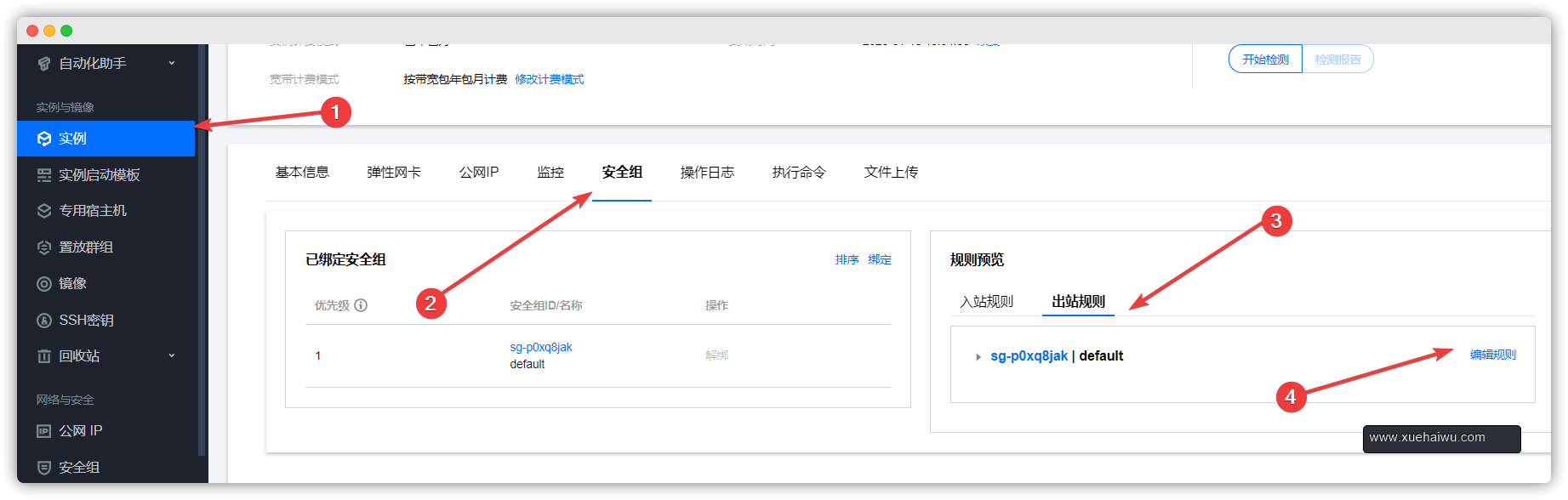
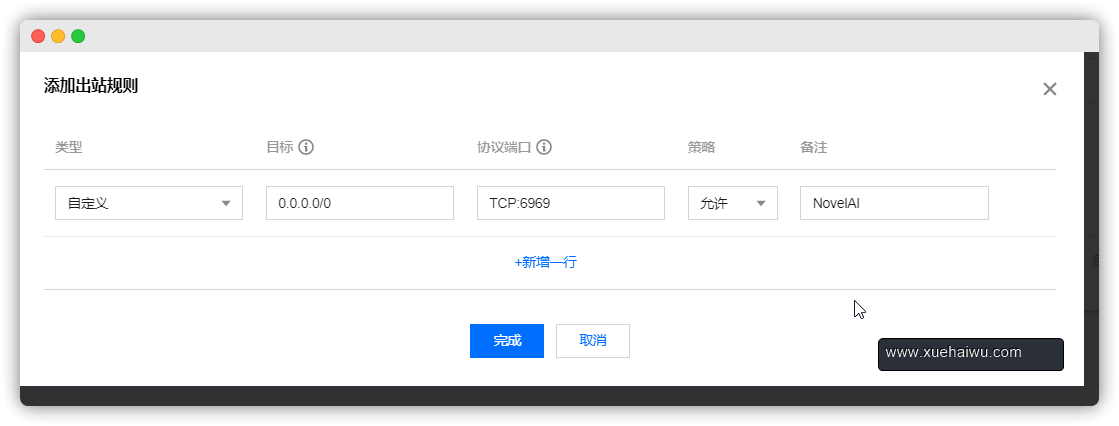
这个表示的是对所有人开放6969TCP协议端口。
正经做站还得进行反向代理操作。而开放端口的目标也得改成代理服务器的IP如10.0.1.8(内网)之类的。
这里先留个小坑吧,后面再填。因为这样已经能够让其他人访问服务了。
